Download notes as jupyter notebook
From adversarial examples to training robust models
In the previous chapter, we focused on methods for solving the inner maximization problem over perturbations; that is, to finding the solution to the problem
We covered three main techniques for doing this: local gradient-based search (providing a lower bound on the objective), exact combinatorial optimization (exactly solving the objective), and convex relaxations (providing a provable upper bound on the objective).
In this Chapter, we return to the min-max problem that we posed in the very first chapter, which corresponds to the task of training a model that is robust to adversarial attacks; in other words, no matter what attack an adversary uses, we want to have a model that performs well (especially if we don’t know the precise strategy that the attacker is going to use; more on this in a second). That is, given some set of input/ouptput pairs $S$, we want to solve the outer minimization problem
The order of the min-max operations is important here. Specially, the max is inside the minimization, meaning that the adversary (trying to maximize the loss) gets to “move” second. We assume, essentially, that the adversary has full knowledge of the classifier parameters $\theta$ (this was implicitly assumed throughout the entire previous section), and that they get to specialize their attack to whatever parameters we have chosen in the outer maximization. The goal of the robust optimization formulation, therefore, is to ensure that the model cannot be attacked even if the adversary has full knowledge of the model. Of course, in practice we may want to make assumptions about the power of the adversary: maybe (or maybe not) it is reasonable to assume they could not solve the integer programs for models that are too large. But it can be difficult to pin down a precise definition of what we mean by the “power” of the adversary, so extra care should be taken in evaluating models against possible “realistic” adversaries.
The good news, in some sense, is that we already did a lot of the hard work in adversarial training, when we described various ways to approximately solve the inner maximization problem. For each of the three methods for solving this inner problem (1) lower bounding via local search, 2) exact solutions via combinator optimziation, and 3) upper bounds via convex relaxations), there would be an equivalent manner for training an adversarially robust system. However, the second option here is not tennable in practice; solving integer programs is already extremely time consuing, and further integrating this into a training procedure (where effectively, we need to compute the solution to an integer program, with the number of variables equal to the number of hidden units in the net, one for each pass over each example in the dataset. This is not a practical approach, and thus we will leave out the possibility of integrating exact combinatorial solution methods into the training procedure. These leaves us with two choices:
- Using lower bounds, and examples constructed via local search methods, to train an (empirically) adversarially robust classifier.
- Using convex upper bounds, to train a provably robust classifier.
There are trade-offs between both approaches here: while the first method may seem less desireable, it will turn out that the first approach empircally creates strong models (with empircally better “clean” performance as well as better robust performance for the best attacks that we can produce. Thus, both sets of strategies are important to consider in determining how best to build adversarially robust models.
Adversarial training with adversarial examples
Perhaps the simplest strategy for training an adversarially robust model is also the one which seems most intuitive. The basic idea (which originally was referred to as “adversarial training” in the machine learning literature, though is also basic technique from robust optimization when viewed through this lense) is to simply create and then incorporate adversarial examples into the training process. In other words, since we know that “standard” training creates networks that are succeptible to adversarial examples, let’s just also train on a few adversarial examples.
Of course, the question arises as to which adversarial examples we should train on. To get at an answer to this question, let’s return to a topic we touch on briefly in the introductory chapter. Supposing we generally want to optimize the min-max objective
using gradient descent, how do we do so? If we want to simply optimize $\theta$ by stochastic gradient descent, this would simply involve computing repeatedly computing the gradient with respect to $\theta$ for the loss function on some minibatch, and taking a step in this negative direction. That is, we want to repeat the update
How do we go about computing this inner gradient? As we mentioned in the first chapter, the answer is given by Danskin’s Theorem, which states that to compute the (sub)gradient of a function containing a max term, we need to simply 1) find the maximum, and 2) compute the normal gradient evaluated at this point. In other words, the relevant gradient is given by
where
Note however, that Danskin’s theorem only technically applies to the case where we are able to compute the maximum exactly. As we learned from the previous section, finding the maximum exactly is not an easy task. And it is very difficult to say anything formally about the nature of the gradient if we do not solve the problem optimally. Nonetheless, what we find in practice is the following: the “quality” of the robust gradient descent procedure is tied directly to how well we are able to perform the maximization. In other words, the better job we do of solving the inner maximization problem, the closer it seems that Danskin’s theorem starts to hold. In other words, the key aspects of adversarial training is incorporate a strong attack into the inner maximization procedure. And projected gradient descent approaches (again, this included the simple variants like projected steepest descent) are the strongest attack that the community has found.
To recap, our strategy is the following:
Although this procedure approximately optimizes the robust loss, which is exactly the target we would like to optimize, in practice it is common to also include a bit of the standard loss (i.e., also take gradient steps in the original data points), as this tends to also slightly improve the performance of the “standard” error of the task. It is also common to randomize over the starting positions for PGD, or else there can be issues with the procedure learning loss surface such that the gradients exactly at the same points point in a “shallow” direction, but very nearby there are points that have the more typical steep loss surfaces of deep networks.
Let’s see how this all looks in code. To start with, we’re going to clone a bunch of the code we used in the previous chapter, including the procedures for building and training the network and for producing adversarial examples.
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
mnist_train = datasets.MNIST("../data", train=True, download=True, transform=transforms.ToTensor())
mnist_test = datasets.MNIST("../data", train=False, download=True, transform=transforms.ToTensor())
train_loader = DataLoader(mnist_train, batch_size = 100, shuffle=True)
test_loader = DataLoader(mnist_test, batch_size = 100, shuffle=False)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
torch.manual_seed(0)
class Flatten(nn.Module):
def forward(self, x):
return x.view(x.shape[0], -1)
model_cnn = nn.Sequential(nn.Conv2d(1, 32, 3, padding=1), nn.ReLU(),
nn.Conv2d(32, 32, 3, padding=1, stride=2), nn.ReLU(),
nn.Conv2d(32, 64, 3, padding=1), nn.ReLU(),
nn.Conv2d(64, 64, 3, padding=1, stride=2), nn.ReLU(),
Flatten(),
nn.Linear(7*7*64, 100), nn.ReLU(),
nn.Linear(100, 10)).to(device)
def fgsm(model, X, y, epsilon=0.1):
""" Construct FGSM adversarial examples on the examples X"""
delta = torch.zeros_like(X, requires_grad=True)
loss = nn.CrossEntropyLoss()(model(X + delta), y)
loss.backward()
return epsilon * delta.grad.detach().sign()
def pgd_linf(model, X, y, epsilon=0.1, alpha=0.01, num_iter=20, randomize=False):
""" Construct FGSM adversarial examples on the examples X"""
if randomize:
delta = torch.rand_like(X, requires_grad=True)
delta.data = delta.data * 2 * epsilon - epsilon
else:
delta = torch.zeros_like(X, requires_grad=True)
for t in range(num_iter):
loss = nn.CrossEntropyLoss()(model(X + delta), y)
loss.backward()
delta.data = (delta + alpha*delta.grad.detach().sign()).clamp(-epsilon,epsilon)
delta.grad.zero_()
return delta.detach()
The only real modification we make is that we modify the adversarial function to also allow for training.
def epoch(loader, model, opt=None):
"""Standard training/evaluation epoch over the dataset"""
total_loss, total_err = 0.,0.
for X,y in loader:
X,y = X.to(device), y.to(device)
yp = model(X)
loss = nn.CrossEntropyLoss()(yp,y)
if opt:
opt.zero_grad()
loss.backward()
opt.step()
total_err += (yp.max(dim=1)[1] != y).sum().item()
total_loss += loss.item() * X.shape[0]
return total_err / len(loader.dataset), total_loss / len(loader.dataset)
def epoch_adversarial(loader, model, attack, opt=None, **kwargs):
"""Adversarial training/evaluation epoch over the dataset"""
total_loss, total_err = 0.,0.
for X,y in loader:
X,y = X.to(device), y.to(device)
delta = attack(model, X, y, **kwargs)
yp = model(X+delta)
loss = nn.CrossEntropyLoss()(yp,y)
if opt:
opt.zero_grad()
loss.backward()
opt.step()
total_err += (yp.max(dim=1)[1] != y).sum().item()
total_loss += loss.item() * X.shape[0]
return total_err / len(loader.dataset), total_loss / len(loader.dataset)
Let’s start by training a standard model and evaluating adversarial error.
opt = optim.SGD(model_cnn.parameters(), lr=1e-1)
for t in range(10):
train_err, train_loss = epoch(train_loader, model_cnn, opt)
test_err, test_loss = epoch(test_loader, model_cnn)
adv_err, adv_loss = epoch_adversarial(test_loader, model_cnn, pgd_linf)
if t == 4:
for param_group in opt.param_groups:
param_group["lr"] = 1e-2
print(*("{:.6f}".format(i) for i in (train_err, test_err, adv_err)), sep="\t")
torch.save(model_cnn.state_dict(), "model_cnn.pt")
0.272300 0.031000 0.666900 0.026417 0.022000 0.687600 0.017250 0.020300 0.601500 0.012533 0.016100 0.673000 0.009733 0.014400 0.696600 0.003850 0.011000 0.705400 0.002833 0.010800 0.696800 0.002350 0.010600 0.707500 0.002033 0.010900 0.714600 0.001783 0.010600 0.708300
model_cnn.load_state_dict(torch.load("model_cnn.pt"))
So as we saw before, the clean error is quite low, but the adversarial error is quite high (and actually goes up as we train the model more). Let’s now do the same thing, but with adversarial training.
model_cnn_robust = nn.Sequential(nn.Conv2d(1, 32, 3, padding=1), nn.ReLU(),
nn.Conv2d(32, 32, 3, padding=1, stride=2), nn.ReLU(),
nn.Conv2d(32, 64, 3, padding=1), nn.ReLU(),
nn.Conv2d(64, 64, 3, padding=1, stride=2), nn.ReLU(),
Flatten(),
nn.Linear(7*7*64, 100), nn.ReLU(),
nn.Linear(100, 10)).to(device)
opt = optim.SGD(model_cnn_robust.parameters(), lr=1e-1)
for t in range(10):
train_err, train_loss = epoch_adversarial(train_loader, model_cnn_robust, pgd_linf, opt)
test_err, test_loss = epoch(test_loader, model_cnn_robust)
adv_err, adv_loss = epoch_adversarial(test_loader, model_cnn_robust, pgd_linf)
if t == 4:
for param_group in opt.param_groups:
param_group["lr"] = 1e-2
print(*("{:.6f}".format(i) for i in (train_err, test_err, adv_err)), sep="\t")
torch.save(model_cnn_robust.state_dict(), "model_cnn_robust.pt")
0.715433 0.068900 0.170200 0.100933 0.020500 0.062300 0.053983 0.016100 0.046200 0.040100 0.011700 0.036400 0.031683 0.010700 0.034100 0.021767 0.008800 0.029000 0.020300 0.008700 0.027600 0.019050 0.008700 0.027900 0.019150 0.008600 0.028200 0.018250 0.008500 0.028300
model_cnn_robust.load_state_dict(torch.load("model_cnn_robust.pt"))
Evaluating robust models
Ok, so with adversarial training, we are able to get a model that has an error rate of just 2.8%, compared to the 71% that our original model had (and increased test accuracy as well, though this is one are where we want to emphasize that this better clean error is an artifact of the MNIST data set, and not something we expect in general). This seems like a resounding success!
Let’s be very very careful, though. Whenever we train a network against a specific kind of attack, it’s incredibly easy to perform well against that particular attack in the future: in a sense, this is just the standard statement about deep network performance: they are incredibly good at predicting precisely the class of data they were trained against. What about if we run some other attack, like FGSM? What if we run PGD for longer? Or with randomization? Or what if someone in the future comes up with some amazing new optimization procedure that works even better (for attacks within the prescribed norm bound)?
Let’s get a sense of this by evaluating our model against some different attacks. Let’s try FGSM first.
print("FGSM: ", epoch_adversarial(test_loader, model_cnn_robust, fgsm)[0])
FGSM: 0.0258
Ok, that is good news. FGSM indeed works worse than even the PGD attack we trained against, because FGSM is really just one step of PGD with a step size of $\alpha = \epsilon$. So it’s not surprising it does worse. Let’s try running PGD for longer.
print("PGD, 40 iter: ", epoch_adversarial(test_loader, model_cnn_robust, pgd_linf, num_iter=40)[0])
PGD, 40 iter: 0.0286
Also good! Error increases a little bit, but well within the bounds of what we might think in reasonable (you can try running for longer, and see that it doesn’t change much … the examples have bit the boundaries of the $\ell_\infty$ ball in most cases, and taking more steps doesn’t change things). But what about if we take more steps with a smaller step size, to try to get a more “fine-grained” attack?
print("PGD, small_alpha: ", epoch_adversarial(test_loader, model_cnn_robust, pgd_linf, num_iter=40, alpha=0.05)[0])
PGD, 40 iter: 0.0284
Ok, we’re getting more confident now. Let’s also add randomization.
print("PGD, randomized: ", epoch_adversarial(test_loader, model_cnn_robust, pgd_linf,
num_iter=40, randomize=True)[0])
PGD, randomized: 0.0284
Alright, so at this point, we’ve done enough evaluations that maybe we are confident enough to put the model online and see if anyone else can actually break it (note: this is not actually the model that was put online, though it was trained in the roughly the same manner). But we should still probably try some different optimizers, try multiple randomized restarts (like we did in the past section), etc.
Note: one evaluation which is not really relevant (except maybe out of curiosity), however, is to evaluate the performance of this robust model under some other perturbation region, say evaluating this $\ell_\infty$ robust model under an $\ell_2$ bounded attack. The model was trained under one single attack model; of course it will not work well to prevent some completely different attack model. If one does desire a kind of “generalization” across multiple attack models, then we need to formally define the set of attack models we care about, and train the model over multiple different draws from these attack models. This is a topic we won’t get in to, except to say that for some classes like multiple different norm bounds, it would be easy to extend the approach to simultaneously defend against e.g. $\ell_1$, $\ell_2$, and $\ell_\infty$ attacks, or something like this. Of course, the real set of attacks we care about (i.e., the set of all images that a human thinks “look reasonably the same”) is extremely hard to characterize, and an excellent subject for future work.
What is happening with these robust models?
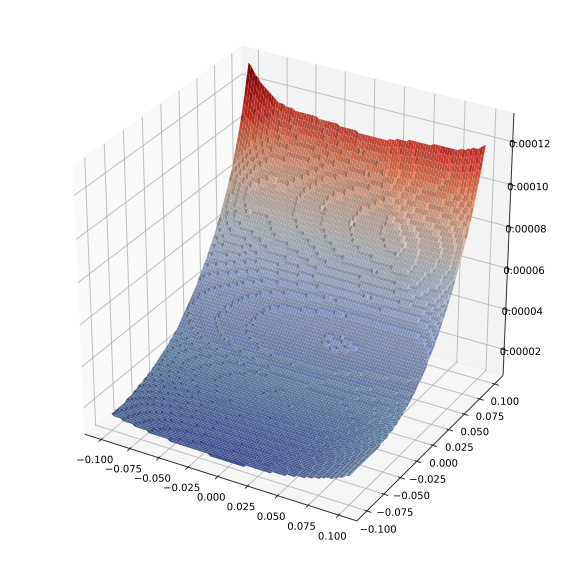
So why do these models work well against robust attacks, and why have some other proposed methods for training robust models (in)famously come up short in this regard? There are likely many answers to this question, but one potential answer can be seen by looking at the loss surface of the trained classifier. Let’s look at a projection of the loss function along two dimensions in the input space (one the direction of the actual gradient, and one a random direction).
for X,y in test_loader:
X,y = X.to(device), y.to(device)
break
def draw_loss(model, X, epsilon):
Xi, Yi = np.meshgrid(np.linspace(-epsilon, epsilon,100), np.linspace(-epsilon,epsilon,100))
def grad_at_delta(delta):
delta.requires_grad_(True)
nn.CrossEntropyLoss()(model(X+delta), y[0:1]).backward()
return delta.grad.detach().sign().view(-1).cpu().numpy()
dir1 = grad_at_delta(torch.zeros_like(X, requires_grad=True))
delta2 = torch.zeros_like(X, requires_grad=True)
delta2.data = torch.tensor(dir1).view_as(X).to(device)
dir2 = grad_at_delta(delta2)
np.random.seed(0)
dir2 = np.sign(np.random.randn(dir1.shape[0]))
all_deltas = torch.tensor((np.array([Xi.flatten(), Yi.flatten()]).T @
np.array([dir2, dir1])).astype(np.float32)).to(device)
yp = model(all_deltas.view(-1,1,28,28) + X)
Zi = nn.CrossEntropyLoss(reduction="none")(yp, y[0:1].repeat(yp.shape[0])).detach().cpu().numpy()
Zi = Zi.reshape(*Xi.shape)
#Zi = (Zi-Zi.min())/(Zi.max() - Zi.min())
fig = plt.figure(figsize=(10,10))
ax = fig.gca(projection='3d')
ls = LightSource(azdeg=0, altdeg=200)
rgb = ls.shade(Zi, plt.cm.coolwarm)
surf = ax.plot_surface(Xi, Yi, Zi, rstride=1, cstride=1, linewidth=0,
antialiased=True, facecolors=rgb)
Let’s look at the loss surface for the standard network.
draw_loss(model_cnn, X[0:1], 0.1)

Very quickly the loss increases substantially. Let’s then compare this to the robust model.
draw_loss(model_cnn_robust, X[0:1], 0.1)

The important point to compare here is the relative $z$ axes (the “bumpiness” in the second figure is just to do this much smaller scale; if put on the same scale the second figure would be completely flat). The robust model has a loss that is quite flat both in the gradient direction (that is the steeper direction), and in the random direction, whereas the traditionally trained model varies quite rapidly both in the gradient direction and (after moving some in the gradient direction) in the random direction. Of course, this is no guarantee that there is no direction of steep cost increase, but it at least gives some hint of what may be happening.
In summary, these models trained with PGD-based adversarial training do appear to be genuinely robust, in that the underlying models themselves have smooth loss surfaces, and not by just a “trick” that hides the true direction of cost increase. Whether more can be said formally about the robustness is a quick that remains to be seen, and a topic of current ongoing research.
Relaxation-based robust training
As a final piece of the puzzle, let’s try to use the convex relaxation methods not just to verify networks, but also to train them. To see why we might want to do this, we’re going to focus here on the interval-based bounds, though all the same factors apply to the linear programming convex relaxation as well, just to a slightly smaller degree (and the methods are much more computationally intensive).
To start, let’s consider using our interval bound to try to verify robustness for the empirically robust classifier we just trained. Remember that a classifier is verified to be robust against an adversarial attack if the optimization objective is positive for all targeted classes. This is done by the following code (almost entirely copied from the previous chapter, but with an additional routine that computes the verified accuracy over batches).
def bound_propagation(model, initial_bound):
l, u = initial_bound
bounds = []
for layer in model:
if isinstance(layer, Flatten):
l_ = Flatten()(l)
u_ = Flatten()(u)
elif isinstance(layer, nn.Linear):
l_ = (layer.weight.clamp(min=0) @ l.t() + layer.weight.clamp(max=0) @ u.t()
+ layer.bias[:,None]).t()
u_ = (layer.weight.clamp(min=0) @ u.t() + layer.weight.clamp(max=0) @ l.t()
+ layer.bias[:,None]).t()
elif isinstance(layer, nn.Conv2d):
l_ = (nn.functional.conv2d(l, layer.weight.clamp(min=0), bias=None,
stride=layer.stride, padding=layer.padding,
dilation=layer.dilation, groups=layer.groups) +
nn.functional.conv2d(u, layer.weight.clamp(max=0), bias=None,
stride=layer.stride, padding=layer.padding,
dilation=layer.dilation, groups=layer.groups) +
layer.bias[None,:,None,None])
u_ = (nn.functional.conv2d(u, layer.weight.clamp(min=0), bias=None,
stride=layer.stride, padding=layer.padding,
dilation=layer.dilation, groups=layer.groups) +
nn.functional.conv2d(l, layer.weight.clamp(max=0), bias=None,
stride=layer.stride, padding=layer.padding,
dilation=layer.dilation, groups=layer.groups) +
layer.bias[None,:,None,None])
elif isinstance(layer, nn.ReLU):
l_ = l.clamp(min=0)
u_ = u.clamp(min=0)
bounds.append((l_, u_))
l,u = l_, u_
return bounds
def interval_based_bound(model, c, bounds, idx):
# requires last layer to be linear
cW = c.t() @ model[-1].weight
cb = c.t() @ model[-1].bias
l,u = bounds[-2]
return (cW.clamp(min=0) @ l[idx].t() + cW.clamp(max=0) @ u[idx].t() + cb[:,None]).t()
def robust_bound_error(model, X, y, epsilon):
initial_bound = (X - epsilon, X + epsilon)
err = 0
for y0 in range(10):
C = -torch.eye(10).to(device)
C[y0,:] += 1
err += (interval_based_bound(model, C, bounds, y==y0).min(dim=1)[0] < 0).sum().item()
return err
def epoch_robust_bound(loader, model, epsilon):
total_err = 0
C = [-torch.eye(10).to(device) for _ in range(10)]
for y0 in range(10):
C[y0][y0,:] += 1
for X,y in loader:
X,y = X.to(device), y.to(device)
initial_bound = (X - epsilon, X + epsilon)
bounds = bound_propagation(model, initial_bound)
for y0 in range(10):
lower_bound = interval_based_bound(model, C[y0], bounds, y==y0)
total_err += (lower_bound.min(dim=1)[0] < 0).sum().item()
return total_err / len(loader.dataset)
Let’s see what happens if we try to use this bound to see whether we can verify that our robustly trained model provably will be insucceptible to adversarial examples in some cases, rather than just empirically so.
epoch_robust_err(test_loader, model_cnn_robust, 0.1)
1.0
Unfortunately, the interval-based bound is entirely vaccous for our (robustly) trained classifier. We’ll save you the disappointment of checking ever smaller values of $\epsilon$, and just mentioned that in order to get any real verification with this method, we need values of $\epsilon$ less than 0.001. For example, for $\epsilon = 0.0001$, we finally achieve a “reasonable” bound.
epoch_robust_err(test_loader, model_cnn_robust, 0.0001)
0.0261
That doesn’t seem particularly useful, and indeed, it is a property of virtually all the relaxation-based verification approaches, is that they are vaccuous when evaluated upon a network trained without knowledge of these bounds. Additionally, these errors tend to accumulate with the depth of the network, precisely because the interval bounds as we have presented them also tend to get looser with each layer of the network (this is why the bounds were not so bad in the previous chapter, when we were applying them to a three-layer network).
Training using provable criteria
So if the verifiable bounds we get are this loose, even for empirically robust networks, of what value could they be? It turns out that, perhaps somewhat surprisingly, if we train a network specifically to minimize a loss based upon this upper bound, we get a network where the bounds are meaningful. This is a somewhat subtle but important point which is worth repeating. In other words, if we train an empirically
To do this, we’re going to use the interval bounds to upper bound the cross entropy loss of a classifier, and then minimize this upper bound. Specifically, if we form a “logit” vector where we replace each entry with the negative value of the objective for a targeted attack, and then take the cross entropy loss of this vector, it functions as a strict upper bound of the original loss. We can implement this as follows.
def epoch_robust_bound(loader, model, epsilon, opt=None):
total_err = 0
total_loss = 0
C = [-torch.eye(10).to(device) for _ in range(10)]
for y0 in range(10):
C[y0][y0,:] += 1
for X,y in loader:
X,y = X.to(device), y.to(device)
initial_bound = (X - epsilon, X + epsilon)
bounds = bound_propagation(model, initial_bound)
loss = 0
for y0 in range(10):
if sum(y==y0) > 0:
lower_bound = interval_based_bound(model, C[y0], bounds, y==y0)
loss += nn.CrossEntropyLoss(reduction='sum')(-lower_bound, y[y==y0]) / X.shape[0]
total_err += (lower_bound.min(dim=1)[0] < 0).sum().item()
total_loss += loss.item() * X.shape[0]
#print(loss.item())
if opt:
opt.zero_grad()
loss.backward()
opt.step()
return total_err / len(loader.dataset), total_loss / len(loader.dataset)
Finally, let’s train our model using this robust loss bound. Note that training rovably robust models is a bit of a tricky business. If we start out immediately by trying to train our robust bound with the full $\epsilon=0.1$, the model will collapse to just predicting equal probability for all digits, and will never recover. Instead, to reliably train such models we need to schedule $\epsilon$ during the training process, starting with a small $\epsilon$ and gradually raising it to the desired level. The schedule we use below was picked rather randomly, and we can do much better with a bit of tweaking, but it serves our basic purpose.
torch.manual_seed(0)
model_cnn_robust_2 = nn.Sequential(nn.Conv2d(1, 32, 3, padding=1, stride=2), nn.ReLU(),
nn.Conv2d(32, 32, 3, padding=1, ), nn.ReLU(),
nn.Conv2d(32, 64, 3, padding=1), nn.ReLU(),
nn.Conv2d(64, 64, 3, padding=1, stride=2), nn.ReLU(),
Flatten(),
nn.Linear(7*7*64, 100), nn.ReLU(),
nn.Linear(100, 10)).to(device)
opt = optim.SGD(model_cnn_robust_2.parameters(), lr=1e-1)
eps_schedule = [0.0, 0.0001, 0.001, 0.01, 0.01, 0.05, 0.05, 0.05, 0.05, 0.05] + 15*[0.1]
print("Train Eps", "Train Loss*", "Test Err", "Test Robust Err", sep="\t")
for t in range(len(eps_schedule)):
train_err, train_loss = epoch_robust_bound(train_loader, model_cnn_robust_2, eps_schedule[t], opt)
test_err, test_loss = epoch(test_loader, model_cnn_robust_2)
adv_err, adv_loss = epoch_robust_bound(test_loader, model_cnn_robust_2, 0.1)
#if t == 4:
# for param_group in opt.param_groups:
# param_group["lr"] = 1e-2
print(*("{:.6f}".format(i) for i in (eps_schedule[t], train_loss, test_err, adv_err)), sep="\t")
torch.save(model_cnn_robust_2.state_dict(), "model_cnn_robust_2.pt")
Train Eps Train Loss* Test Err Test Robust Err 0.000000 0.829700 0.033800 1.000000 0.000100 0.126095 0.022200 1.000000 0.001000 0.119049 0.021500 1.000000 0.010000 0.227829 0.019100 1.000000 0.010000 0.129322 0.022900 1.000000 0.050000 1.716497 0.162200 0.828500 0.050000 0.744732 0.092100 0.625100 0.050000 0.486411 0.073800 0.309600 0.050000 0.393822 0.068100 0.197800 0.050000 0.345183 0.057100 0.169200 0.100000 0.493925 0.068400 0.129900 0.100000 0.444281 0.067200 0.122300 0.100000 0.419961 0.063300 0.117400 0.100000 0.406877 0.061300 0.114700 0.100000 0.401603 0.061500 0.116400 0.100000 0.387260 0.059600 0.111100 0.100000 0.383182 0.059400 0.108500 0.100000 0.375468 0.057900 0.107200 0.100000 0.369453 0.056800 0.107000 0.100000 0.365821 0.061300 0.116300 0.100000 0.359339 0.053600 0.104200 0.100000 0.358043 0.053000 0.097500 0.100000 0.354643 0.055700 0.101500 0.100000 0.352465 0.053500 0.096800 0.100000 0.348765 0.051500 0.096700
It’s not going to set any records, but what we have here is an MNIST model that where no $\ell_\infty$ attack of norm bounded by $\epsilon=0.1$ will ever be able to cause the classifier to experience more than 9.67% error on the test set of MNIST (acheiving a “clean” error of 5.15%). And just how bad can a real adversarial attack do? It’s of course hard to say for sure, but let’s see what PGD does.
print("PGD, 40 iter: ", epoch_adversarial(test_loader, model_cnn_robust_2, pgd_linf, num_iter=40)[0])
PGD, 40 iter: 0.0779
So somewhere right in the middle. Note also that training these provably robust models is a challenging task, and a bit of tweaking (even still using interval bounds) can perform quite a bit better. For now, though, this is sufficient to make our point that we can obtain non-trivial provable bounds for trained networks.
The long road ahead (a.k.a. leaving MNIST behind)
The presentation here might lead you to believe that robust models are seemingly pretty close to their traditional counterparts (what’s a few percentage points here or there). However, while we hope that we were able to get you excited about the potential of these methods, it’s important to emphasize that on large-scale problems we are nowhere close to building robust models that can match standard models in terms of their performance. Unfortunately, a lot of the apparent strength of these models came from our use of MNIST, where it is particularly easy to create robust
Even on a dataset like CIFAR10, for example, the best known robust models that can handle a perturbation of $8/255 = 0.031$ color values achieve an (empirical) robust error of of 55%, and the best provably robust models have an error greater than 70%. On the flipside, the choices we have with regards to training procedures, network architecture, regularization, etc, have barely been touched in the robust optimization context. All our architecture choices come from what has been best for standard training, but these likely are no longer optimal architectures for robust training. Finally, as we will highlight in the next chapter, there is substantial benefit to be had from robust models right now, even if true robust performance still remains ellusive.